大數據技術作為信息時代的重要支柱,已成為各行各業數字化轉型的核心驅動力。其中,數據處理技術是大數據知識體系中的關鍵環節,掌握好數據處理技術是成為大數據專業人才的必經之路。本文將圍繞大數據處理技術,系統介紹其知識體系和學習路徑,為學習者提供清晰的方向。
一、大數據處理技術知識體系
1. 數據采集與集成
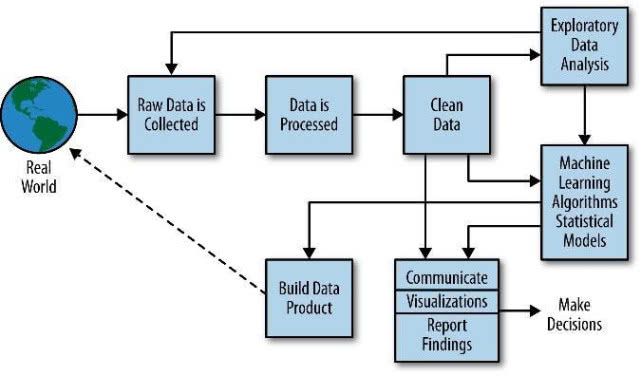
數據采集是大數據處理的第一步,涉及從多種數據源獲取數據的技術。主要包括:
- 日志采集工具(如Flume、Logstash)
- 網絡爬蟲技術
- 消息隊列(如Kafka、RabbitMQ)
- 數據同步工具(如Sqoop、DataX)
2. 數據存儲與管理
大數據存儲技術需要解決海量數據的持久化問題:
- 分布式文件系統(HDFS)
- NoSQL數據庫(HBase、Cassandra、MongoDB)
- 數據倉庫(Hive、ClickHouse)
- 新型存儲引擎(如Lakehouse架構)
3. 數據計算與處理
這是大數據處理的核心環節,包括:
- 批處理技術:MapReduce、Spark Core
- 流處理技術:Spark Streaming、Flink、Storm
- 圖計算:GraphX、Giraph
- 內存計算:Spark
4. 數據查詢與分析
提供數據訪問和分析能力:
- SQL-on-Hadoop技術(Hive、Impala)
- 交互式查詢引擎(Presto、Druid)
- OLAP分析工具
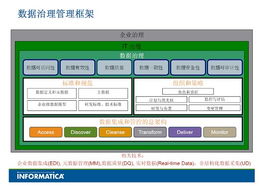
5. 數據治理與質量
確保數據的可靠性和可用性:
- 元數據管理
- 數據血緣分析
- 數據質量監控
- 數據安全與隱私保護
二、大數據處理技術學習建議
- 基礎階段(1-3個月)
- 掌握Linux操作系統基礎命令
- 學習Java或Scala編程語言
- 理解分布式系統基本原理
- 熟悉SQL語言和數據庫概念
- 核心框架學習(3-6個月)
- Hadoop生態圈:重點掌握HDFS、MapReduce、YARN
- Spark核心技術:RDD、DataFrame、Spark SQL
- 消息隊列:Kafka原理與應用
- 數據倉庫:Hive的使用和優化
- 進階實踐(6個月以上)
- 搭建偽分布式或完全分布式集群
- 參與實際數據處理項目
- 學習性能調優和故障排查
- 關注新興技術如Flink、Iceberg等
- 持續學習建議
- 關注開源社區動態和技術演進
- 閱讀官方文檔和源碼
- 參與技術社區討論
- 考取相關認證(如Cloudera、Hortonworks認證)
三、實踐項目推薦
- 日志分析系統:使用Flume采集日志,Kafka作為消息隊列,Spark Streaming進行實時處理
- 用戶行為分析:基于Hive構建數據倉庫,進行用戶畫像和推薦分析
- 電商數據處理:構建完整的ETL流程,實現銷售數據的多維度分析
學習大數據處理技術需要循序漸進,從基礎理論到框架使用,再到項目實踐。建議學習者在掌握單個組件后,嘗試將它們組合成完整的數據處理流水線,這樣才能真正理解大數據處理的完整流程。同時,保持對新技術的敏感度,不斷更新知識體系,方能在快速演進的大數據領域保持競爭力。